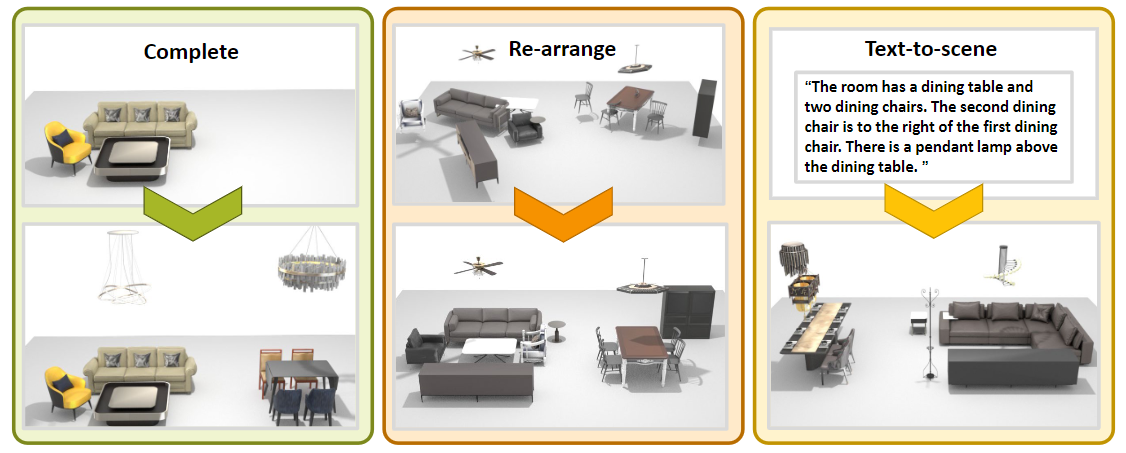
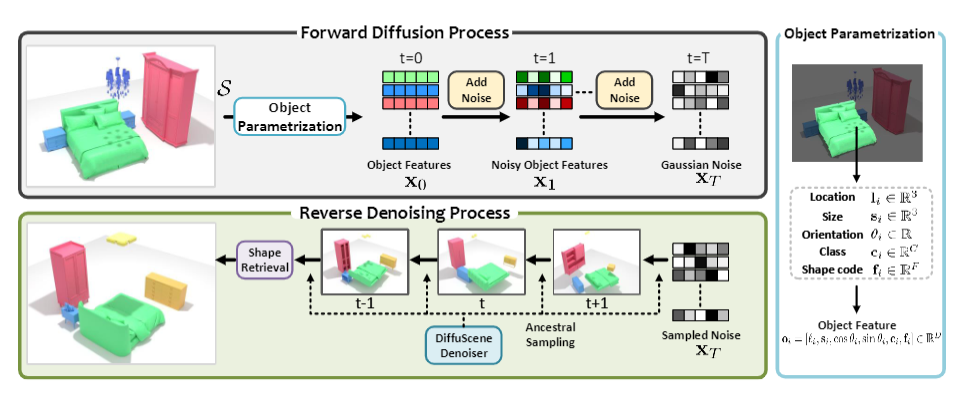
Given a 3D scene S, we obtain its fully-connected scene graph x0, by parametrizing each object as a graph node storing all object attributes i.e., location, size, orientation, class label,
and latent shape code.
Based on a set of all possible x0, we propose DiffuScene, a denoising diffusion probabilistic model
for 3D scene graph generation. In the forward process, we gradually add noise to x0 until we obtain a standard Gaussian
noise xT. In the reverse process i.e. generative process, a denoising network iteratively cleans the noisy graph using ancestral
sampling. Finally, we use the denoised object features to perform shape retrieval for realistic scene synthesis.