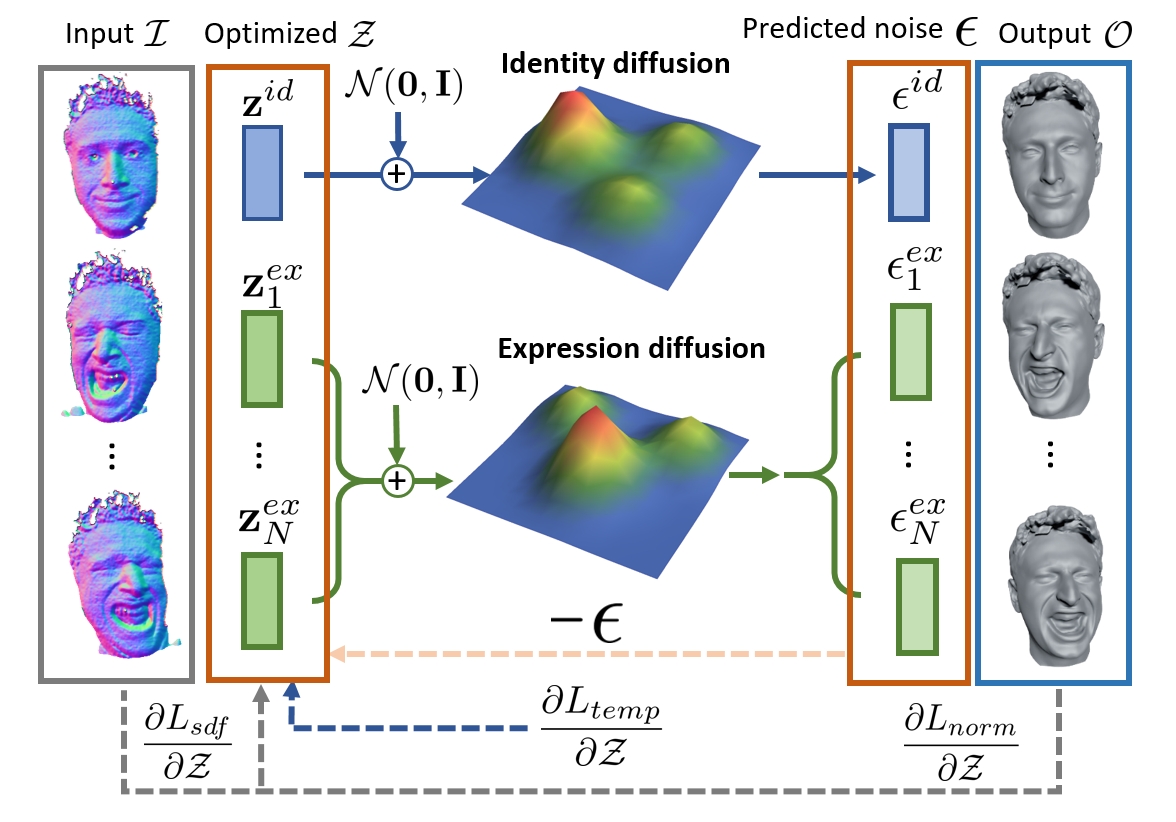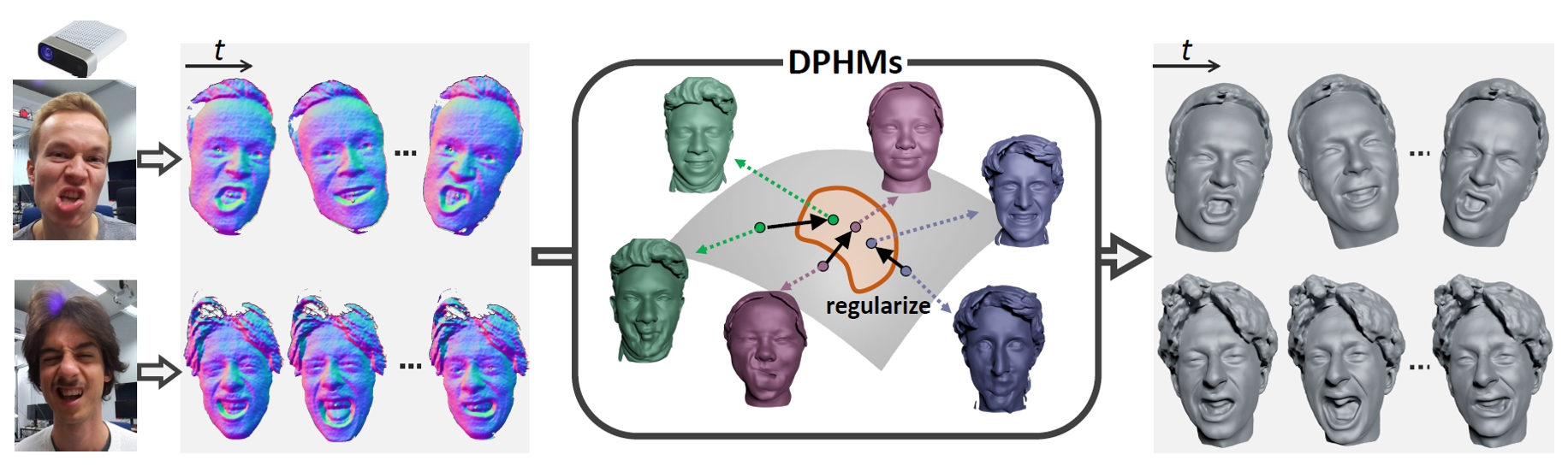
We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstruction heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is under-constrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods, and demonstrate improved head identity reconstruction as well as robust expression tracking.
We collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions.
Our approach demonstrates the ability to reconstruct realistic head avatars with hairs and accurately capture intricate facial expressions such as extreme mouth movements and eyelid movements.